こんにちは! フロントエンドエンジニアのもりやです。
ママリではよりユーザーにとってわかりやすく情報を伝えるべく、4/22 からママリ内の人気記事などを動画にし配信する取り組みをはじめました。
今回、動画配信にあたって AWS 上で動画変換と配信を行ったので、使用したサービスやシステム構成などを解説しようと思います。
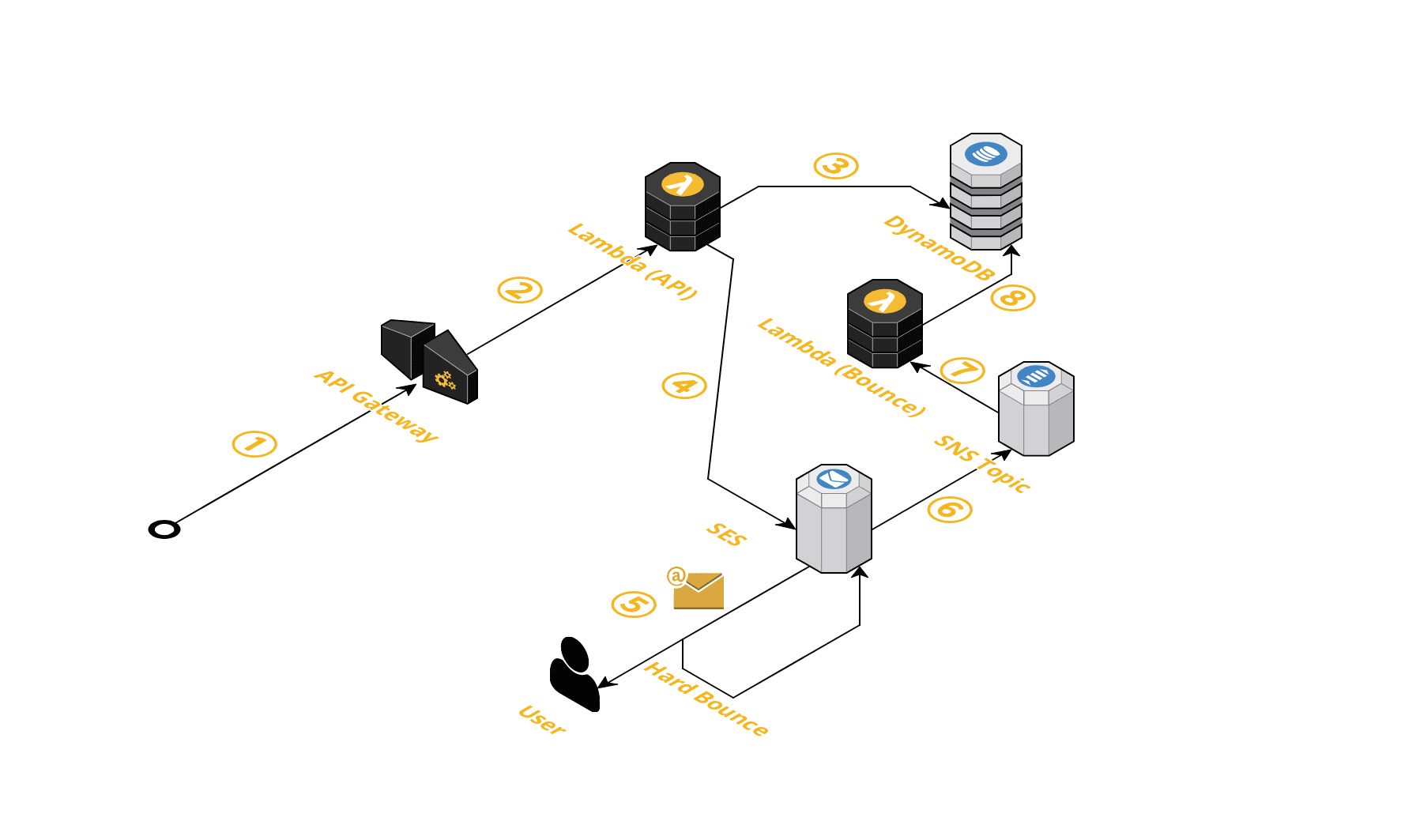
システムの全体像
AWSサービスを使って、以下のような構成で作りました。

※この図は動画の配信のみに絞っています。動画の情報をアプリに配信するAPIなどは別にあります。
大まかに説明するとこんな感じです。
CloudFront + S3を使ってHTTP (HLS) で配信MediaConvertを使ってMP4形式の動画をHLS 形式へ変換API Gateway + Lambdaを使って動画変換のAPIを提供DynamoDBを使って動画の情報を保存
以下、詳しく説明します。
動画のフォーマット
配信にあたり、まず動画をどのように配信するかを決めました。 今回配信する動画は、数十秒程度がメインなのでそのまま動画ファイルを配信する方法も検討しました。 ただ、1分を超える動画もありますし、全部ダウンロードしないと再生できないというのは体験的に良くないのでストリーミングでの配信に決めました。
動画のストリーミング配信は全く知見がなかったので色々調べたところ、以下の2つが主流のようです。
- HLS (HTTP Live Streaming)
- MPEG-DASH(ISO/IEC 23009)
あまり詳細な仕様までは調べきれていないですが、いろいろ調べた結果、HLSの方がシンプル、MPEG-DASHはDRMなどの複雑な要件にも対応できるがその分仕様も複雑、という印象でした。
今回の配信要件はシンプルで、iOS/Android でもネイティブのエンジニアの方から再生できることが可能であることを確認したのでHLSを採用することにしました。 ちなみに、HLSはAppleが提唱している規格なので、iOSは当然対応していますし、HLS形式の動画はSafariで直接開くことも可能です。(他のブラウザは対応していません)
CloudFront + S3
HLSは配信にあたって静的なHTTPサーバーにファイルを配置するだけで良いので、よくある CloudFront + S3で配信しています。
MediaConvert
S3に置いてある動画ファイルを変換して、変換した動画ファイルをS3に出力してくれるサービスです。 今回の動画配信で最も重要なサービスでした。
ジョブの作成
MediaConvert は「ジョブ」という単位で変換を実行します。 ジョブは、以下のような入力と出力を設定して、変換の詳細を設定します。
変換の全体像

入力が一つに対して、出力が複数あることが分かるかと思います。 例えば、1つの動画からHLSとMPEG-DASHの2つを同時に変換して出力することができます。
ちなみに入力も複数作れるようなのですが、今回複数入力を使う用途はなく私にも用途が分からないので、説明は割愛します。 (動画の結合とか、複数の動画を横に並べて結合したりできるんでしょうか?)
入力の設定

入力は S3に配置した動画ファイルのパスを指定します。
他にもたくさん設定項目がありますが、今回はここの設定以外は特に使っていません。
動画は奥が深い・・・。
出力の設定(動画)

出力先の S3プレフィックスを入力します。
(※プレフィックスであり、このままの名前で出力されるわけではありません。)
また、下の方の「出力」欄を見ると、2つの出力があるのが分かるかと思います。 例えばHLSであれば、複数のビットレートの動画を1つの配信に含め、クライアントがネットワークの状況に応じて切り替えることができます。 そういった場合に、1つの出力グループに対して、複数の出力を設定することができます。 (ちなみに、今回のママリの配信では諸事情により1つの出力にしています)

各出力に対して、動画の詳細を設定できます。 こちらも大量の設定項目がありますが、主に使ったのは以下の2つです。
- ビデオコーデックと解像度
- ビットレート
他は特にいじらなくても、デフォルトのままで特に問題ありませんでした。
出力の設定(キャプチャ画像)
今回、動画に配信する際にサムネイル用の画像も一緒に作りたいということで、動画内から1秒おきにキャプチャ画像を作り、その中から適切な画像を選んで配信する、という方法を取りました。
例えば、30秒の動画なら、30枚のJPEG画像が出力され、その中からサムネイルとして良さそうなものを選ぶ、という感じです。

こんな感じの出力設定をします。
画質にあまり拘らなければ、フレームレートを調整すれば大丈夫です。
1/1で1秒に1枚、という設定になります。
変換の実行
設定が完了したら、変換を実行します。 以下のようにジョブリストに表示され「COMPLETE」と表示されれば完了です。 ちなみに設定にエラーがある場合は「ERROR」と表示されます。

変換が完了すると S3にはこのように出力されます。

※ジョブ作成時に設定したプレフィックスなどによって出力先は変わります。
出力先を CloudFrontで配信している S3バケットにしておくと、変換完了後にすぐインターネットからアクセスできるので便利でした。
API Gateway + Lambda
AWS SDK でも実行できるのですが、curlやスクリプト、管理画面などから使いやすいように、シンプルなAPIを提供するようにしました。
- アップロードの情報を提供するAPI
- S3 の Pre-Signed URLを使って、アップロードに必要な一時URLを生成して返却するAPIです。
- アップロード自体は、アクセス元の責務にしてます。
- 変換をリクエストするAPI
MediaConvertにジョブを作るAPIです。- ジョブIDなどは
DynamoDBで管理しています。
- 動画情報を取得するAPI
MediaConvertに問い合わせて、ジョブの情報を取得して返却します。- 変換が完了している場合は、インターネットからアクセスできるURLなども返却します。
なお、API Gatewayは API Key でアクセスを制限しています。
変換作業
今回は、1本辺り数十秒程度がメインの動画を200本以上、再生時間だと2時間以上の動画ファイルをアップロード&変換しました。
curlなどで手動アップロードも可能ですが、時間がかかる、ヒューマンエラーが発生しやすい、設定ミスなどで再変換したい場合でも再実行しやすくしたい、といった目的のため Node.jsでスクリプトを書きました。
詳細は省きますが Node.jsを使いアップロードを最大10並列で実行するスクリプトを書いて実行しました。
大体変換完了まで16分ほどで終わったので、かなり早くできました。
MediaConvertは複数実行すると並列に変換してくれるので、単に2時間の動画を変換するよりも早く終わります。便利ですね!
料金
CloudFront での配信料金
これは動画に限らないですが CloudFrontからインターネットへの転送は 1GB あたり 0.114 USD かかります。
$1 = 107円で、100GB の配信をしたとすると
0.114USD * 100GB * 107円 = 約1,220円かかります。
MediaConvert での変換料金
今回の肝である MediaConvert での変換にはどのぐらいの料金がかかるのか紹介します。 最近のスマホは解像度が高くなっているので、MediaConvert の算定方法だと 4K に該当する画質で変換しました。
フレームレートは <30fpsでやったので、
1分間の変換料金は 0.034USD になります。
$1 = 107円で、60分の動画を変換した場合、
0.034USD * 60分 * 107円 = 約218円になります。
めっちゃ安いですね!
VODやってる会社さんとかはわかりませんが、今回のように小規模な動画配信を行う場合、 動画変換の開発や設定、サーバー維持費など考慮すればめちゃくちゃコスパいいサービスだな、と感じました。
その他
S3API GatewayLambdaDynamoDBなどの料金などがありますが、CloudFrontでの配信料金に比べると微々たるもの、もしくは無料枠で収まる程度でしかなかったので、省略します。
おわりに
今回初めての動画配信でしたが、HLS で配信し、AWS のサービスを使うことでかなり容易に構築や配信準備を行うことができました。
動画配信は敷居が高いイメージでしたが、今回のようなシンプルな配信と AWSのサービスを組み合わせる場合は割と楽にできます。
未知の領域に踏み込んでみるのは楽しいですね。 コネヒトでは、新しいことにどんどんチャレンジしたいエンジニアを募集中です!